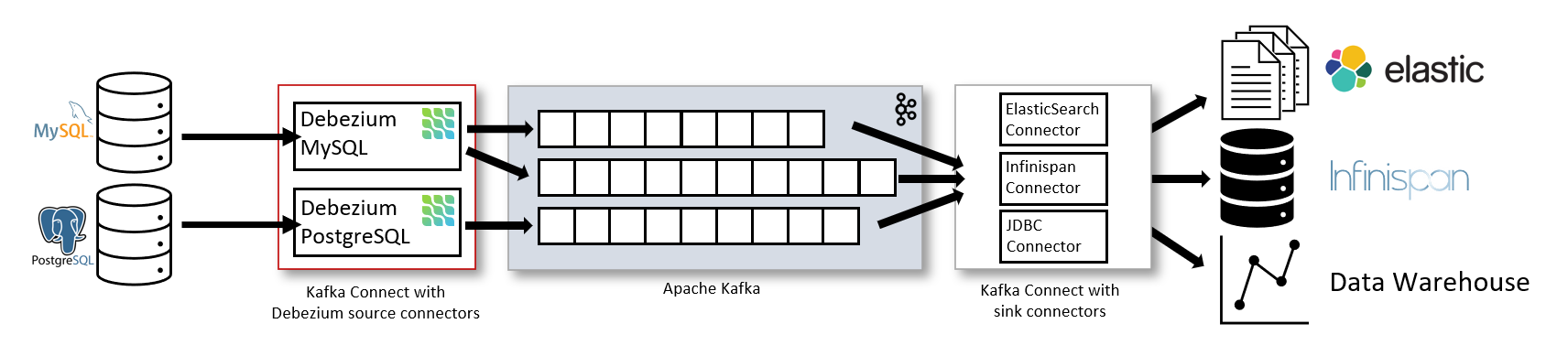
Khi xây dựng hệ thống phân tán micro-service, vấn đề khó khăn nhất là đồng bộ dữ liệu giữa các module phục vụ truy vấn dữ liệu hoặc xây dựng data streaming để thực hiện việc xử lý và biến đổi dữ liệu.
Mô hình triển khai chung của debezium
Ở đặc thù dự án hiện tại ta chỉ sử dụng Debezium PostgreSQL để bắt các thay đổi của PostgreSQL server và đẩy vào Kafka.
Dùng để bắt tất cả các thay đổi ở từng dòng của các bảng trong các schemas. Ngay lần đầu tiên Debezium kết nối tới database, nó sẽ thực hiện chụp lại tất cả schemas của database, sau khi việc sao chụp thành công, nó sẽ tiếp tục bắt các lệnh insert, update, và delete dữ liệu đã được commit vào trong PostgreSQL database sau đó tạo ra các khối sự kiện truyền đi thông qua Kafka và được bắt ở đầu sink connector. Tại đây các sự kiện sẽ được cập nhật vào các hệ thống lưu trữ khác hoặc được xử lý trực tiếp.
Bước 1: Cấu hình PostgreSQL server để bật wal_level lên logical
wal_level = logical
max_replication_slots = 10
max_wal_senders = 10
sau đó restart lại PostgreSQL server
Bước 2: Tạo replica user
CREATE ROLE debezium WITH LOGIN REPLICATION PASSWORD 'password';
Bước 3: Cấp quyền truy cập cho user này
host replication debezium 0.0.0.0/0 md5
Bước 4: Cài đặt Kafka connect, hiện đang triển khai bằng cách cài đặt trên Kubernetes
Thông thường nguyên nhân nằm ở Kafka do cấu hình Kafka được thiết đặt kích thước tối đa của mỗi gói dữ liệu đẩy qua. Cần phải điều chỉnh lại kích thước của dữ liệu cho phép qua Kafka